gc current block 2 way - gc current block 3 way
Block oriented waits are the most common wait
events in the cluster wait events. The block oriented wait event statistics
indicate that the requested block was served from the other instances. In a two
– node cluster environment a message is transferred to the current holder of
the block and holder ships the block to the requestor. In a cluster environment
with more than two nodes, the request for the block is sent to the holder of
the block through the resource master and includes an additional message.
The average wait time and total wait time
should be considered when being alerted to performance issues where these
particular waits have a high impact. Usually, either interconnects or load
issues of SQL execution against a large shared working ser can be found the
root cause. The following are the most common block oriented waits
gc current block 2 – way ( 2 Node RAC
Environment)
gc current block 3 – way ( 3 or More Node RAC Environment )
Pictorial Description of the steps involved in
the above wait events in exclusive mode and shared mode.
gc current block 2 – way ( Exclusive Mode)

gc current block 2 – way ( Shared Mode)

gc current block 3 – way ( Exclusive Mode)

gc current block 3 – way ( Shared Mode)

gc current block busy & gc cr block busy
Top 5 Wait Events (RAC) - gc current block busy & gc cr block busy
gc current block busy - When a request needs a block in current mode, it sends a request to the master instance. The requestor evenutally gets the block via cache fusion transfer. However sometimes the block transfer is delayed due to either the block was being used by a session on another instance or the block transfer was delayed because the holding instance could not write the corresponding redo records to the online logfile immediately.
One can use the session level dynamic performance views v$session and v$session_event to find the programs or sesions causing the most waits on this events
select a.sid , a.time_waited , b.program , b.module from v$session_event a , v$session b where a.sid=b.sid and a.event='gc current block busy' order by a.time_waited;
gc cr block busy - When a request needs a block in CR mode , it sends a request to the master instance. The requestor evenutally gets the block via cache fusion transfer. However sometimes the block transfer is delayed due to either the block was being used by a session on another instance or the block transfer was delayed because the holding instance could not write the corresponding redo records to the online logfile immediately.
One can use the session level dynamic performance views v$session and v$session_event to find the programs or sesions causing the most waits on this events
select a.sid , a.time_waited , b.program , b.module from v$session_event a , v$session b where a.sid=b.sid and a.event='gc cr block busy' order by a.time_waited;

This event indicates significant write/write contention. If it appears like the below in TOP 5 list of AWR
Ensure that the log writer (lgwr) is tuned. In our situation planning for appropriate application partitioning to multiple instances avoided the contention. We will see more of the RAC realted wait events in the other posts.
gc current block busy - When a request needs a block in current mode, it sends a request to the master instance. The requestor evenutally gets the block via cache fusion transfer. However sometimes the block transfer is delayed due to either the block was being used by a session on another instance or the block transfer was delayed because the holding instance could not write the corresponding redo records to the online logfile immediately.
One can use the session level dynamic performance views v$session and v$session_event to find the programs or sesions causing the most waits on this events
select a.sid , a.time_waited , b.program , b.module from v$session_event a , v$session b where a.sid=b.sid and a.event='gc current block busy' order by a.time_waited;
gc cr block busy - When a request needs a block in CR mode , it sends a request to the master instance. The requestor evenutally gets the block via cache fusion transfer. However sometimes the block transfer is delayed due to either the block was being used by a session on another instance or the block transfer was delayed because the holding instance could not write the corresponding redo records to the online logfile immediately.
One can use the session level dynamic performance views v$session and v$session_event to find the programs or sesions causing the most waits on this events
select a.sid , a.time_waited , b.program , b.module from v$session_event a , v$session b where a.sid=b.sid and a.event='gc cr block busy' order by a.time_waited;

This event indicates significant write/write contention. If it appears like the below in TOP 5 list of AWR
Ensure that the log writer (lgwr) is tuned. In our situation planning for appropriate application partitioning to multiple instances avoided the contention. We will see more of the RAC realted wait events in the other posts.
gc cr block lost / gc current block lost
TOP 5 Timed Events - gc cr block lost / gc current block lost

“Lost Blocks”: IP Packet Reassembly Failures
netstat –s
Global cache lost blocks statistics ("gc cr block
lost" and/or "gc current block lost") for each node in the
cluster as well as aggregate statistics for the cluster represent a problem or
inefficiencies in packet processing for the interconnect traffic. These
statistics should be monitored and evaluated regularly to guarantee efficient
interconnect Global Cache and Enqueue Service (GCS/GES) and cluster processing.
Any block loss indicates a problem in network packet processing and should be
investigated.
The vast majority of escalations attributed to RDBMS
global cache lost blocks can be directly related to faulty or mis-configured
interconnects. “lost blocks” at the RDBMS level, responsible for 64% of
escalations.

Misconfigured or Faulty Interconnect Can
Cause:
•
Dropped packets/fragments
•
Buffer overflows
•
Packet reassembly failures or timeouts
•
Ethernet Flow control kicks in
•
TX/RX errors
“Lost
Blocks”: NIC Receive Errors
Db_block_size
= 8K
ifconfig
–a:
eth0
Link encap:Ethernet HWaddr
00:0B:DB:4B:A2:04
inet
addr:130.35.25.110 Bcast:130.35.27.255 Mask:255.255.252.0
UP
BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX
packets:21721236 errors:135 dropped:0 overruns:0 frame:95
TX
packets:273120 errors:0 dropped:0 overruns:0 carrier:0
“Lost Blocks”: IP Packet Reassembly Failures
netstat –s
Ip:
84884742 total packets received
…
84884742 total packets received
…
1201 fragments dropped after timeout
…
3384 packet reassembles failed
…
3384 packet reassembles failed
Detailed Explanation of the this wait event
can be found at Metalink - gc block lost diagnostics [ID 563566.1]
Top 5 Timed Foreground Events - Library Cache Lock & Library Cache Pin
Library cache lock will be obtained on database objects referenced during parsing or compiling of SQL or PL/SQL statements (table, view, procedure, function, package, package body, trigger, index, cluster, and synonym). The lock will be released at the end of the parse or compilation.
I am not discussing more on the theory part of the this wait event as I have discussed more about them in my previous blog. You can find the much detailed explanation of possible reasons and solutions with the below link
http://orakhoj.blogspot.com/2011/10/top-5-timed-foreground-events-library_17.html
Here I am just discussing about the recent issue we faced in our load test environment. When we ran the load with X amount of SGA we see DB Time increased to very high value and found Library Cache Lock and Library Cache Pin as TOP 2 Wait events.


Solutions:
We just increased the SGA to Y amount and re ran the same load which
has given wonderful results. The DB time has reduced to a considerable
amount and Library Cache Lock has disappeared from the TOP wait event.
So the solutions which I discussed in the above link, here it are the
practical implementation. The increase in Shared Pool via increasing the SGA has solved the problem to get rid of this wait event.


op 5 Timed Events - gc cr failure
gc cr failure – This wait event is triggered when a CR ( Consistent
Read) block is requested from the holder of the block and a failure
status message is received. This happens where there are unforeseen
events such as lost block or checksum or an invalid block request or
when the holder cannot process the request. One will see multiple
timeouts for the place holder wait like gc cr request before receiving
gc cr failure event. One can query system statistics view v$sysstat for
gc blocks lost or gc claim blocks lost.
Failure is not an option in cluster communications because lot messages or block may potentially trigger node evictions.

In the above case this wait event is because of gc buffer busy as the node holding the block requested is busy and cannot process the request.
Let us understand how Consistent Read (CR) requests are handled in RAC to get more clarity and why the nodes get busy fulfilling the requests. When an instance needs to generate a CR version of the current block, the block can be either in the local or remote cache. If the latter, then LMS ( Lock Manager Server) on the other instance will try to create the CR block, when the former, the foreground process executing the query will perform the CR block generation. When a CR version is created, the instance or instances needs to read the transaction table and undo blocks from the rollback /undo segment that are referenced in the active transaction table of the block. Sometimes this cleanout/rollback process may cause several lookups of remote undo headers and undo blocks. The remote undo header and undo block lookups will result in a gc cr request . Also as undo headers are frequently accessed, a buffer wait may also occur.
We got rid of these kind of wait events after reducing the traffic between the nodes by pointing the applications which are depended on each specific tables to specific nodes.
Failure is not an option in cluster communications because lot messages or block may potentially trigger node evictions.

In the above case this wait event is because of gc buffer busy as the node holding the block requested is busy and cannot process the request.
Let us understand how Consistent Read (CR) requests are handled in RAC to get more clarity and why the nodes get busy fulfilling the requests. When an instance needs to generate a CR version of the current block, the block can be either in the local or remote cache. If the latter, then LMS ( Lock Manager Server) on the other instance will try to create the CR block, when the former, the foreground process executing the query will perform the CR block generation. When a CR version is created, the instance or instances needs to read the transaction table and undo blocks from the rollback /undo segment that are referenced in the active transaction table of the block. Sometimes this cleanout/rollback process may cause several lookups of remote undo headers and undo blocks. The remote undo header and undo block lookups will result in a gc cr request . Also as undo headers are frequently accessed, a buffer wait may also occur.
We got rid of these kind of wait events after reducing the traffic between the nodes by pointing the applications which are depended on each specific tables to specific nodes.
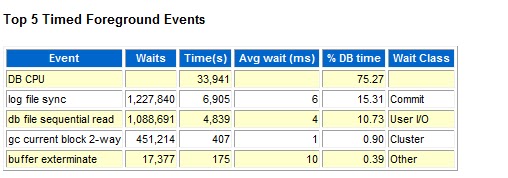
Top 5 Timed Foreground Events - Buffer Exterminate
Buffer Exterminate - Buffer exterminate wait event is caused when using
Oracle's "automatic memory management" (AMM) when the MMON process
shrinks the data buffer cache to re-allocate that RAM for another SGA
region. The experience has indicated that AMM resize operations can hurt
overall database performance especially the OLTP environments, and you
may want to consider turning off AMM which will relieve the buffer
exterminate waits, and manually adjusting your SGA regions.
If you see this in the TOP 5 Times Events, One has to look into v$sga_resize_ops and v$memory_resize_ops and see how many times it is occurring and effecting the performance of your database. If one sees more events of these and especially during your peak times of database one has to turn of the feature adjusting manually the corresponding SGA and PGA sizes.

If you want to analyze Oracle's use of memory and look at various memory resizing operations you can use the V$MEMORY_RESIZE_OPS view. This view contains a list of the last 800 SGA resize requests handled by Oracle. Here is an example:
SELECT parameter, initial_size, target_size, start_time FROM v$memory_resize_ops WHERE initial_size > = 0 and final_size > = 0 ORDER BY parameter, start_time;
This shows that Oracle has made a number of changes to the database cache and the shared pool, over a pretty short period of time. These changes will often decrease as the database stays up for a longer period of time, and you will often see changes as the load profile of the database changes, say from being report heavy to OLTP heavy.
Please find below the various tables and thier descriptions to check the information in the database.
V$MEMORY_DYNAMIC_COMPONENTS - Displays information on the current size of all automatically tuned and static memory components, with the last operation (for example, grow or shrink) that occurred on each.
V$SGA_DYNAMIC_COMPONENTS -- Displays the current sizes of all SGA components, and the last operation for each component.
V$SGA_DYNAMIC_FREE_MEMORY -- Displays information about the amount of SGA memory available for future dynamic SGA resize operations.
V$MEMORY_CURRENT_RESIZE_OPS -- Displays information about resize operations that are currently in progress. A resize operation is an enlargement or reduction of the SGA, the instance PGA, or a dynamic SGA component.
V$SGA_CURRENT_RESIZE_OPS -- Displays information about dynamic SGA component resize operations that are currently in progress.
V$MEMORY_RESIZE_OPS -- Displays information about the last 800 completed memory component resize operations, including automatic grow and shrink operations for SGA_TARGET and PGA_AGGREGATE_TARGET.
V$SGA_RESIZE_OPS -- Displays information about the last 800 completed SGA component resize operations.
If you see this in the TOP 5 Times Events, One has to look into v$sga_resize_ops and v$memory_resize_ops and see how many times it is occurring and effecting the performance of your database. If one sees more events of these and especially during your peak times of database one has to turn of the feature adjusting manually the corresponding SGA and PGA sizes.
If you want to analyze Oracle's use of memory and look at various memory resizing operations you can use the V$MEMORY_RESIZE_OPS view. This view contains a list of the last 800 SGA resize requests handled by Oracle. Here is an example:
SELECT parameter, initial_size, target_size, start_time FROM v$memory_resize_ops WHERE initial_size > = 0 and final_size > = 0 ORDER BY parameter, start_time;
This shows that Oracle has made a number of changes to the database cache and the shared pool, over a pretty short period of time. These changes will often decrease as the database stays up for a longer period of time, and you will often see changes as the load profile of the database changes, say from being report heavy to OLTP heavy.
Please find below the various tables and thier descriptions to check the information in the database.
V$MEMORY_DYNAMIC_COMPONENTS - Displays information on the current size of all automatically tuned and static memory components, with the last operation (for example, grow or shrink) that occurred on each.
V$SGA_DYNAMIC_COMPONENTS -- Displays the current sizes of all SGA components, and the last operation for each component.
V$SGA_DYNAMIC_FREE_MEMORY -- Displays information about the amount of SGA memory available for future dynamic SGA resize operations.
V$MEMORY_CURRENT_RESIZE_OPS -- Displays information about resize operations that are currently in progress. A resize operation is an enlargement or reduction of the SGA, the instance PGA, or a dynamic SGA component.
V$SGA_CURRENT_RESIZE_OPS -- Displays information about dynamic SGA component resize operations that are currently in progress.
V$MEMORY_RESIZE_OPS -- Displays information about the last 800 completed memory component resize operations, including automatic grow and shrink operations for SGA_TARGET and PGA_AGGREGATE_TARGET.
V$SGA_RESIZE_OPS -- Displays information about the last 800 completed SGA component resize operations.
Top 5 Timed Foreground Events - control file sequential read
control file sequential read
This wait events occurs If one has all their control files on a disk with high disk I/O then access to control file for updating the SCN etc may result in this wait.Reading from the control file. This happens in many cases. For example, while
1)Making a backup of the control files
2)Sharing information (between instances) from the control file
3)Reading other blocks from the control files
4)Reading the header block
Wait Time: The wait time is the elapsed time of the read

In the above u see control file sequential read is on the top 5 list with wait class as System I/O. In this case if has come on the top as the no of transactions hitting the system have crossed 1000 Transactions Per Second(TPS) and the database is an high commit oriented OLTP system. That is the reason we see log file sync as one of the top 5 wait events.
Solution: Identify the Control file locations and try to place them on faster disks or less activity disks.
SQL ordered by Physical Reads (UnOptimized) from 11g AWR
The 'SQL ordered by Physical Reads (UnOptimized)' section would look similar to the following

Optimized Read Requests are read requests that are satisfied from
the Smart Flash Cache ( or the Smart Flash Cache in OracleExadata (Note that despite same name, concept and use of 'Smart
Flash Cache' in Exadata is different from 'Smart Flash Cache' in
Database Smart Flash Cache)). Read requests that are satisfied from
this cache are termed 'optimized' since they are provided much faster
than requests from disk (implementation uses solid state device (SSD)
technology). Additionally, read requests accessing Storage
Indexes using smart scans in Oracle Exadata (and significantly
reducing I/O operations) also fall under the category
'optimized read requests' since they avoid reading blocks that do
not contain relevant data.
Note that the 'Physical Read Reqs' column in the 'SQL ordered by Physical Reads (UnOptimized)' section is the number I/O requests and not the number of blocks returned. Be careful not to confuse these with the Physical Reads statistics from the AWR section 'SQL ordered by Reads', which counts database blocks read from the disk not actual I/Os (a single I/O operation may return many blocks from disk)
If you look at the example 'SQL ordered by Reads' section below from same AWR report for database not using smart cache,notice the physical reads

Note the difference between 'Physical Reads' in the 'SQL ordered by Reads' and the 'Physical Read Reqs' in the 'SQL ordered by Physical Reads (UnOptimized)' section above for the SQL with "SQL_ID=8q4akpck0nxgg" from same AWR report.
Top 5 Timed Foreground Events - Streams miscellaneous event
The Streams miscellaneous event will be
renamed to "Waiting for additional work from the logfile" to better
describe the activity from Oracle release 11.2.0.2.x See detail in BugDB
12341046 for more information
In AWR (Automatic Workload Repository) you may see a Streams
miscellaneous event as a top resource consumers in the wait class OTHER , when
running Oracle Goldengate (OGG) EXTRACT with the parameter TRANLOGOPTIONS
DBLOGREADER set.

As
of OGG 11.1.1.0.0 onwards the extract process can use the OCIPOGG
logreader module if the TRANLOGOPTIONS DBLOGREADER parameter is set in the
extract parameter file.
NOTE : to use the logreader functionality your Oracle release must also be 10.2.0.5+ or 11.2.0.2+
NOTE : to use the logreader functionality your Oracle release must also be 10.2.0.5+ or 11.2.0.2+
CAUSE
The
cause of the issue has been identified in unpublished Bug 12341046. It is
caused by incorrectly associating the wait for a redo log with the
"Streams miscellaneous event" rather than the IDLE wait event
"Streams capture: waiting for archive log"
Solution
To
confirm that this is the case you can do the following
1.
Get the operating system pocess ids of the processes which are waiting on
the 'Streams miscellaneous event'
connect
/ as sysdba
set
markup html on
spool
processes.html
select
s.sid, s.serial#, s.process, p.spid, p.pid, p.program from v$session s,
v$session_wait sw, v$process p where s.sid=sw.sid and sw.event =
'Streams miscellaneous event' and s.paddr=p.addr;
spool off
2. Attach to the processes and generate sql trace
spool off
2. Attach to the processes and generate sql trace
oradebug
setospid <spid>;
oradebug TRACEFILE_NAME
oradebug event 10046 trace name context forever, level 12
--Trace for 5 minutes
oradebug event 10046 trace name context off
In
the tracefile for processes associated with the GG Extract process you should
see entries of the form
WAIT
#0: nam='log file sequential read' ela= 2823 log#=0 block#=1
blocks=1 obj#=-1 tim=8507422526613 <<< READING the redo logs
WAIT
#0: nam='log file sequential read' ela= 221 log#=0 block#=235 blocks=2
obj#=-1 tim=8507422526918<<< READING the redo logs
WAIT
#0: nam='log file sequential read' ela= 233 log#=0 block#=235
blocks=2 obj#=-1 tim=8507422527161<<< READING the redo logs
WAIT
#0: nam='Streams miscellaneous event' ela= 488302 TYPE=16 p2=0
p3=0 obj#=-1 tim=8507423015480
TYPE=16
confirms that we are waiting for redo and indicates that the fix for
unpublished Bug 12341046 will resolve the issue
Bug 12341046
is fixed in Oracle RDBMS 12.1 onwards
Analyzing & Interpreting AWR Report
db file scattered read, db file sequential read & direct read wait events explanation
db file scattered read
This event signifies that the user process is reading buffers into the SGA buffer cache and is waiting for a physical I/O call to return. A db file scattered read issues a scattered read to read the data into multiple discontinuous memory locations of buffer cache.A scattered read is usually a multi block read. It can occur for a fast full scan (of an index) in addition to a full table scan.
The db file scattered read wait event identifies that a full scan is occurring. When performing a full scan into the buffer cache, the blocks read are read into memory locations that are not physically adjacent to each other. Such reads are called scattered read calls, because the blocks are scattered throughout memory. This is why the corresponding wait event is called 'db file scattered read'. multiblock (up to DB_FILE_MULTIBLOCK_READ_COUNT blocks) reads due to full scans into the buffer cache show up as waits for 'db file scattered read'
db file sequential read
This event signifies that the user process is reading a buffer into the SGA buffer cache and is waiting for a physical I/O call to return. A sequential read is a single-block read.
Single block I/Os are usually the result of using indexes. Rarely, full table scan calls could get truncated to a single block call due to extent boundaries, or buffers already present in the buffer cache. These waits would also show up as 'db file sequential read'.
direct path read
The session is waiting for a direct read to complete. A direct read is a physical I/O from a data file that bypasses the buffer cache and reads the data block directly into process-private memory.
If asynchronous I/O is supported (and in use), then Oracle can submit I/O requests and continue processing. Oracle can then pick up the results of the I/O request later and wait on "direct path read" until the required I/O completes.
If asynchronous I/O is not being used, then the I/O requests block until completed but these do not show as waits at the time the I/O is issued. The session returns later to pick up the completed I/O data but can then show a wait on "direct path read" even though this wait will return immediately. Hence this wait event is very misleading because: • The total number of waits does not reflect the number of I/O requests • The total time spent in "direct path read" does not always reflect the true wait time.
All three wait events are graphically represented below.

For all the three wait events Check the following
V$SESSION_WAIT parameter columns:
·
P1 - The absolute file number
·
P2 - The block being read
·
P3 - The number of blocks (should be greater than 1)
Solution:
Reducing Waits / Wait times:
Block
reads are fairly inevitable so the aim should be to minimize un-necessary IO.
This is best achieved by good application design and efficient execution plans.
Changes to execution plans can yield orders of magnitude changes in
performance. Tweaking at system level usually only achieves percentage gains.
The following points may help:
- Check for SQL using unselective index scans
- A larger buffer cache can help - test this by actually increasing << Parameter: DB_CACHE_SIZE>> (or <<Parameter:DB_BLOCK_BUFFERS>> if still using that). Never increase the SGA size if it may induce additional paging or swapping on the system.
- A less obvious issue which can affect the IO rates is how well data is clustered physically. Eg: Assume that you frequently fetch rows from a table where a column is between two values via an index scan. If there are 100 rows in each index block then the two extremes are:
- Each of the table rows is in a different physical block (100 blocks need to be read for each index block)
- The table rows are all located in the few adjacent blocks (a handful of blocks need to be read for each index block)
Pre-sorting
or re-organizing data can help to tackle this in severe situations.
- See if partitioning can be used to reduce the amount of data you need to look at.
- It can help to place files which incur frequent index scans on disks which have are buffered by a cache of some form. eg: flash cache or hardware disk cache. For non-ASM based databases put such datafiles on a filesystem with an O/S file system cache. This can allow some of Oracles read requests to be satisfied from the cache rather than from a real disk IO.
Response Times will vary from system
to system. As an example, the following could be considered an acceptable
average:
10 ms for MultiBlock Synchronous
Reads
5 ms for SingleBlock Synchronous Reads
3 ms for 'log file parallel write'
5 ms for SingleBlock Synchronous Reads
3 ms for 'log file parallel write'
This is based on the premise that
multi block IO may require more IO subsystem work than a single block IO and
that, if recommendations are followed, redo logs are likely to be on the
fastest disks with no other concurrent activity
IO Wait Outliers (Intermittent Short IO Delays)
Even though the average
IO wait time may be well in the accepted range, it is possible that
"hiccups" in performance may be due to a few IO wait outliers.
In 12c the following views contain entries corresponding to I/Os that have
taken a long time (more than 500 ms)
In 11g, the information in the Wait Event Histogram sections of the AWR report
may be useful in determining whether there are some IOs that are taking longer
than average
Log write waits over 500ms are also written to the LGWR trace file
For more information on outliers in 12C see:
For more information on outliers in 12C see:
Oracle Database Online
Documentation 12c Release 1 (12.1)Database Administration
Database Reference
V$IO_OUTLIER
V$LGWRIO_OUTLIER
V$KERNEL_IO_OUTLIER (only populated on Solaris)
Identifying IO Response Time
Oracle records the
response time of IO operations as the "Elapsed Time" indicated
in specific wait events and statistics."Response time" and
"elapsed time" are synonymous and interchangeable terms in this
context.
Below is a list of some
of the more popular wait events and their typical acceptable wait times (not an
exhaustive list)
Wait Event
|
R/W
|
Synchronous
/Asynchronous |
Singleblock/
Multiblock |
Elapsed Time
(with 1000+ waits per hour) |
control file parallel write
|
Write
|
Asynchronous
|
Multi
|
< 15ms
|
control file sequential read
|
Read
|
Synchronous
|
Single
|
< 20 ms
|
db file parallel read
|
Read
|
Asynchronous
|
Multi
|
< 20 ms
|
db file scattered read
|
Read
|
Synchronous
|
Multi
|
< 20 ms
|
db file sequential read
|
Read
|
Synchronous
|
Single
|
< 20 ms
|
direct path read
|
Read
|
Asynchronous
|
Multi
|
< 20 ms
|
direct path read temp
|
Read
|
Asynchronous
|
Multi
|
< 20 ms
|
direct path write
|
Write
|
Asynchronous
|
Multi
|
< 15 ms
|
direct path write temp
|
Write
|
Asynchronous
|
Multi
|
< 15 ms
|
log file parallel write
|
Write
|
Asynchronous
|
Multi
|
< 15 ms
|
Exadata
Related
|
||||
cell smart table scan
|
Read
|
Asynchronous
|
Multi
|
< 1 ms
|
cell single block physical read
|
Read
|
Synchronous
|
Single
|
< 1 ms
|
cell multiblock physical read
|
Read
|
Synchronous
|
Multi
|
< 6 ms
|