CLUSTERING FACTOR DEMYSTIFIED PART – I
CLUSTERING FACTOR DEMYSTIFIED PART – I
The clustering_factor measures how synchronized an index is with the data in a table. A table with a high clustering factor is out-of-sequence with the rows and large index range scans will consume lots of I/O. Conversely, an index with a lowclustering_factor is closely aligned with the table and related rows reside together of each data block, making indexes very desirable for optimal access.
Rules for Oracle indexing
To understand how Oracle chooses the execution plan for a query, you need to first learn how the SQL optimizer decides whether or not to use an index.
Oracle provides a column called clustering_factor in the dba_indexes view that provides information on how the table rows are synchronized with the index. The table rows are synchronized with the index when the clustering factor is close to the number of data blocks and the column value is not row-ordered when theclustering_factor approaches the number of rows in the table.
For queries
that access common rows with a table (e.g. get all items in order 123),
unordered tables can experience huge I/O as the index retrieves a
separate data block for each row requested.

If we group like rows together (as measured by the clustering_factor in dba_indexes) we can get all of the row with a single block read because the rows are together.
Note: As we see grouping related rows together can make a huge
reduction in disk I/O, and Oracle has embraced this row sequencing idea
in 10g and beyond with thesorted hash cluster, a fully supported way to ensure that related rows always reside together on the same data block.
Today we have choices for row sequencing. We can even group related rows from several tables together with multi-table hash clusters, or we can use single table clusters, or manual row re-sequencing (CTAS with ORDER BY) to achieve this goal:
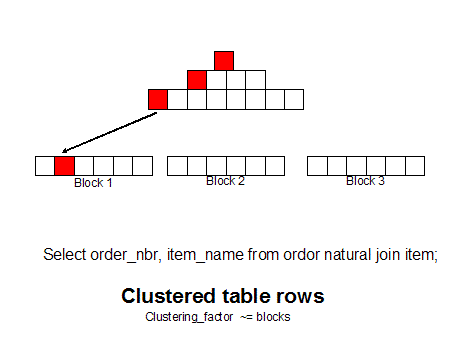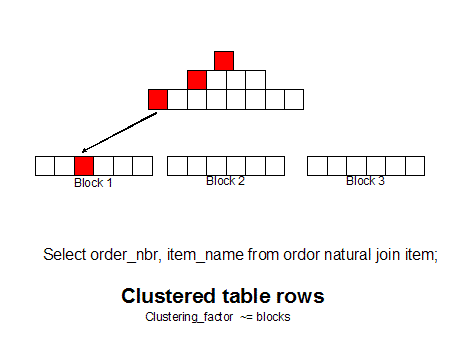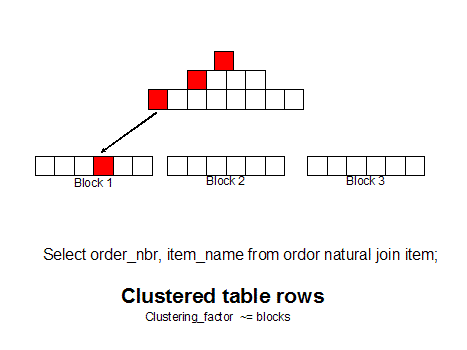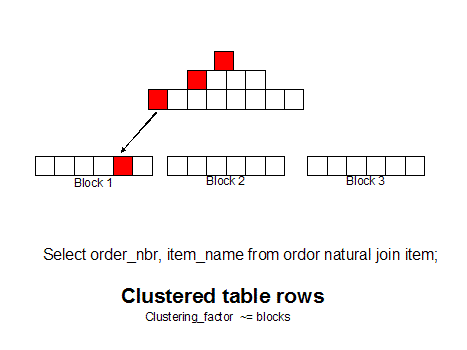
select
customer_name
from
customer
where
ustomer_state = ‘New Mexico’;
Here, the decision to use an index vs. a full-table scan is at least partially determined by the percentage of customers in New Mexico. An index scan is faster for this query if the percentage of customers in New Mexico is small and the values are clustered on the data blocks.
Why, then, would a CBO choose to perform a full-table scan when only a small number of rows are retrieved? Perhaps it is because the CBO is considering the clustering of column values within the table.
Four factors work together to help the CBO decide whether to use an index or a full-table scan: the selectivity of a column value, the db_block_size, the avg_row_len, and the cardinality. An index scan is usually faster if a data column has high selectivity and a low clustering_factor.
 |
| This column has small rows, large blocks, and a low clustering factor.In the real-world, many Oracle database use the same index for the vast majority of queries. If these queries always to an index range scan (e.g. select all orders for a customer), them row re-sequencing for a better clustering_factor can greatly reduce Oracle overhead: |

Oracle provides several storage mechanisms to fetch a customer row and all related orders with just a few row touches:
- Sorted hash clusters - New in 10g, a great way to sequence rows for super-fast SQL
- Multi-table hash cluster tables - This will cluster the customer rows with the order rows, often on a single data block.
- Periodic reorgs in primary index order - You can use the dbms_redefinitionutility to periodically re-sequence rows into index order.
On the other hand, as the clustering_factor nears the number of rows in the table, the rows fall out of sync with the index. This high clustering_factor, where the value is close to the number of rows in the table (num_rows), indicates that the rows are out of sequence with the index and an additional I/O may be required for index range scans.
Even when a column has high selectivity, a high clustering_factor, and smallavg_row_len, there is still indication that column values are randomly distributed in the table, and an additional I/O will be required to obtain the rows. An index range scan would cause a huge amount of unnecessary I/O as shown in below, thus making a full-table scan more efficient.
 |
| This column has large rows, small blocks, and a high clustering factor. |
=========================================================
SYMPTOMS:
There
are several symptoms that point to the buffer cache as a problem. If
the following are observed in the Top 5 Timed Events (V$session_event,
v$system_event), then investigate further:
- LATCH: CACHE BUFFER CHAINS (CBC): This generally points to hot blocks in the cache.
- LATCH: CACHE BUFFER LRU CHAINS: contention indicates that the buffer cache is too small, and block replacement is excessive.
- BUFFER BUSY WAITS: This is almost always an application tuning issue. Multiple processes are requesting the same block.
- DB FILE SEQUENTIAL READS : wait for a single block to be read synchronously from disk
- DB FILE SCATTERED READS : wait for multiple blocks to be read concurrently from disk
- DB FILE PARALLEL READS : wait for a synchronous multiblock read
- FREE BUFFER WAITS: When the DBWn processes do not make sufficient free buffers to meet the demand, free buffer waits are seen.
Let’s discuss above wait events in detail.
As I discussed in my earlier article on buffer cache architecture,
the buffer cache holds in memory versions of data blocks for faster
access. Each buffer in the buffer cache has an associated element the
buffer header array, externalized as x$bh. Buffer headers keep track of
various attributes and state of buffers in the buffer cache. These
buffer headers are chained together in a doubly linked list and linked
to a hash bucket. There are many hash buckets (# of buckets are derived
and governed by _db_block_hash_buckets parameter). Access (both inspect
and change) to these hash chains are protected by cache buffers chains
latches.
Further, buffer headers can be linked and delinked from hash buckets dynamically.
Here is a simple algorithm to access a buffer:
1. Hash the data block address (DBAs: a combination of tablespace, file_id and block_id) to find hash bucket.
2. Get the CBC latch protecting the hash bucket.
3.
If success (CBC latch obtained), walk the hash chain, reading buffer
headers to see if a specific version of the block is already in the
chain.
If specific version of block found,
access the buffer in buffer cache, with protection of buffer pin/unpin actions.
If specific version of block not found,
Get cache buffer LRU chain latch to find a free buffer in buffer cache,
Get cache buffer LRU chain latch to find a free buffer in buffer cache,
unlink the buffer header for that buffer from its current chain,
link that buffer header with this hash chain,
release the latch and
read block in to that free buffer in buffer cache with buffer header pinned.
If not success(CBC latch not obtained) ,
spin for spin_count times and
go to step 2.
If that latch was not got with spinning, then
sleep (with exponentially increasing sleep time with an upper bound),
wake up, and go to step 2.
Let;s talk about them one by one .
LATCH : CACHE BUFFER CHAINS
The CBC latches are used when searching for, adding, or removing a buffer from the buffer cache.
Multiple users looking for the same blocks or blocks in the same hash
bucket and hence trying to obtain the latch on the same bucket. Such
blocks are called hot blocks. Wait event can occur if
- Latch can’t be obtained due to contention.
-
Latch was obtained by one session and was held for long while walking
the chain as the chain was long . Hence, others trying to obtain the
latch have to wait.
Some of the activities that can cause this wait event are:
1. Multiple users trying to read code/description etc. from look up tables.
Soln:
- Identify the hot block
. Segments by logical reads in AWR report
. v$segment_statistics (object_name, statistic_name, value)
This query shows the top 10 statistic values, by object and statistic name.
> SELECT *
FROM (SELECT owner, object_name,
object_type, statistic_name, sum(value)
FROM V$SEGMENT_STATISTICS
GROUP BY owner, object_name, object_type, statistic_name
ORDER BY SUM(value) DESC)
WHERE ROWNUM <= 10;
- Find out the file# (P1) and block# (P2) from v$session_wait
SQL:>select sid, event, P1 File#, P2 Block#
from v$session_wait
where event like ‘%buffer busy%';
- Find out the segment whose data is on this file/block
SQL>select owner, segment_name
from dba_extents
where file_id = &file#
and &block# between block_id and block_id+blocks-1;
- Modify the application to use PL/SQL to read the look up table once and store code/descriptions in local variables which can be accessed later rather than reading from the table.
2. Simultaneous update/select operations on the same block:
CBC
latch contention can become worse if a session is modifying the data
block that users are reading because readers will clone a block with
uncommitted changes and roll back the changes in the cloned block. SInce
all these clone copies will go in the same bucket and be protected by
the same latch, length of the cbc chain gets longer, it takes more time
to walk the chain , latch is held for a longer time and hence users
trying to obtain the latch have to wait for longer period.
Soln:
- Modify the application to commit frequently so that CR clones need not be created.
3. When multiple users are running nested loop joins on a table and accessing the table driven into via an index. Since the NL join is basically a
For all rows in i
look up a value in j where j.field1 = i.val
end loop
then
table j’s index on field1 will get hit for every row returned from i.
Now if the lookup on i returns a lot of rows and if multiple users are
running this same query then the index root block is going to get
hammered on the index j(field1).
e.g.
select t1.val, t2.val
from t1, t2
where t1.c1 = {value}
and t2.id = t1.id;
Here, if there are a large no. of rows in table t1 where c1 = value, Oracle will repeatedly hit the index on table t2 (id).
In
this case SQL statements with high BUFFER_GETS (logical reads) per
EXECUTION are the main culprits. Multiple concurrent sessions are
executing the same inefficient SQL that is going after the same data
set.
SOLUTION:
———-
Reducing contention for the cache buffer chains latch will usually
require reducing logical I/O rates by tuning and minimizing the I/O
requirements of the SQL involved. High i/O rates could be a sign of a
hot block (meaning a block highly accessed).
- Find SQL ( Why is application hitting the block so hard? ). SQL by buffer gets in AWR report
- Replace Nested loop joins with hash join
- Hash Partition the index with hot block
- Create a reverse key index
- Use Hash clusters
4. This can also result from the use of sequences if cache option is not used.
Soln:
- Create sequences with cache option.
5. Inefficient SQL
Multiple concurrent sessions are executing the same inefficient SQL that is going after the same data set.
Soln:
Reducing
contention for the cache buffer chains latch will usually require
reducing logical I/O rates by tuning and minimizing the I/O requirements
of the SQL involved. High I/O rates could be a sign of a hot block
(meaning a block highly accessed).
- Spread data out to reduce contention
- Export the table, increase the PCTFREE significantly,
and import the data. This minimizes the number of rows per block,
spreading them over many blocks. Of course, this is at the expense of
storage and full table scans operations will be slower
- For indexes, you can rebuild them with higher PCTFREE values, bearing in mind that this may increase the height of the index.
- Consider reducing the block size :
If the current block size is 16K, you may move the table or recreate
the index in a tablespace with an 8K block size. This too will
negatively impact full table scans operations. Also, various block
sizes increase management complexity.
6. Index leaf chasing from very many processes scanning the same unselective index with very similar predicate.
Soln:
- Modify the application to use more selective predicate/index.
7. Large size of buffer cache so that length of hash chains increases and hence time taken to walk the chain increasing thereby increasing latch contention.
Soln:
- Increase the parametere _db_block_hash_buckets so that no. of buckets increases and hence length of hash chain decreases.
BUFFER BUSY WAITS
—————————
This is the second wait event which is encountered in case of logical
I/O. It is a wait event for a buffer that is being used in an unsharable
way or is being read into the buffer cache. Buffer busy waits are there
when latch is obtained on the hash bucket but the buffer is “busy” as
- Another session is reading the block into the buffer
- Another session holds the buffer in an incompatible mode to our request
These
waits indicate read/read, read/write, or write/write contention. Buffer
busy waits are common in an I/O-bound Oracle system.This wait can be
intensified by a large block size as more rows can be contained within
the block.
These waits can be on :
- Data Blocks : Multiple sessions trying to update/delete rows in same block
- Segment Header : Multiple sessions trying to insert records in same segment
- Undo header : A lot of undo is being generated and hence contention on undo segment header.
- Undo block : Contention on the same undo block as multiple users querying the records in same undo block
Diagnosis :
- Top 5 events in AWR report
-
Buffer wait statistics section of AWR report- shows the type of data
block, the wait is on i.e. data block, segment header or undo block
(v$waitstat)
- V$session_event
- V$system_event
- v$waitstat
Solution :
- Wait on Data Blocks (v$waitstat) : If the wait is on the data block, we can move “hot” data to another block to avoid this hot block or use smaller blocks (to reduce the No. of rows per block, making it less “hot”).
. Identify segments with buffer busy waits
v$segment_statistics (object_name, statistic_name, value)
. Eliminate HOT blocks from the application.
. Check for repeatedly scanned / unselective indexes.
. Reduce the number of rows per block : Try rebuilding the object with a higher PCTFREE and lower PCTUSED
. Check for ‘right- hand-indexes’ (indexes that get inserted into at the same point by many processes) – Rebuild as reverse key indexes
. Increase INITRANS and MAXTRANS (where users are simultaneously accessing the same block),
When a DML occurs on a block, the lock byte is set in the block
and any user accessing the record(s) being changed must check the
Interested Transaction List (ITL) for info regarding building the before
image of the block. The Oracle database writes info into the block,
including all users who are “interested” in the state of the block, in
the ITL. Increasing INITRANS will create the space in the block to
allow multiple ITL slots (for multiple user acces).
- Wait on segment header (v$waitstat)
. If using Manual segment space management,
– Increase of number of FREELISTs and FREELIST GROUPs
– Increase the PCTUSED-to-PCTFREE gap
– Use ASSM
- Wait on undo header
. Use Automatic undo management.
. If using manual undo management, increase no. of rollback segments .
- Wait on undo block
. Try to commit more often
. Use larger rollback segments or larger undo tablespace.
To practically simulate buffer busy wait and identify the hot block, visit this link.
LATCH: CACHE BUFFER LRU CHAIN
.
This is the first wait which occurs in case of physical I/O i.e. server
process is unable to find the desired block in buffer cache and hence
needs to read it from disk into cache. Before reading the block, it
searches for the free buffers by scanning the LRU list. To scan the LRU
list, it must obtain latch on the LRU chain. The cache buffer lru chain
latch is also acquired when writing a buffer back to disk, specifically
when trying to scan the LRU (least recently used) chain containing all
the dirty blocks in the buffer cache (to delink from LRU list and link
to WRITE LIST – MAIN).
Diagnosis :
- Top 5 timed events in AWR report
- v$session_event
- v$system_event
This wait is encountered when
1. Multiple users issuing Statements that repeatedly scan large unselective indexes or perform full table scans and hence scan LRU chain to look for free buffers.
Soln:
- Identify SQL causing large amount of logical I/O – SQL by buffer gets in AWR report
- Tune SQL to reduce no. of buffers required
2. Insufficient size of buffer cache which
leads to frequent aging out of the cached blocks which need to be
reread from the disk requiring search for free buffers and hence need to
obtain LRU latch.
Soln:
- Use AMM/ASMM
- Increase Db buffer cache size as per
. ADDM recommendation
. v$db_cache_advice
-
Increase the parameter _db_block_lru_latch to increase the no. of
latches protecting lru chain so that contention on lru chain is reduced.
FREE BUFFER WAITS
After the latch has been obtained on LRU list and server process is
scanning the LRU list to search for free buffers, we are waiting for a
free buffer but there are none available in the cache because there are
too many dirty buffers in the cache.
Causes :
1. Buffer cache is too small
Soln:
- Use AMM/ASMM
- Increase DB buffer cache size as per
. ADDM recommendation
. v$db_cache_advice
2. DBWR is slow in writing modified buffers to disk and is unable to keep up to the write
requests.
Soln:
- Increase I/O bandwidth by striping the datafiles.
- If asynchronous I/O is supported
. Enable asynchronous I/O (DISK_ASYNCH_IO=true)
– if multiple CPU’s are there,
Increase the no. of database writers (DB_WRITER_PROCESSES)
else
Configure I/O slaves (set DBWR_IO_SLAVES to non zero )
else
Configure I/O slaves (set DBWR_IO_SLAVES to non zero )
3. Large sorts and full table scans and / or scan of unselective indexex are
filling the cache with modified blocks faster than the DBWR is able
to write to disk. As the data is not pre-sorted, the data for a key
value is scattered across multiple blocks and hence more no. of blocks
are read to get records for a key.
Soln:
- Pre-sorting or reorganizing data can help
READ WAITS
Waits encountered when data blocks are being read physically from the
disk. These waits are always present even in well tuned Databases.
Following strategy should be employed to decide of tuning is required:
- Compare total read time with the baseline value.
- If total wait time is excessive fraction of total DB time, two cases can be there
1. Average time for each read is normal but no. of disk reads are high
Soln:
– Try to decrease no. of reads : Find SQL statements issuing most logical/physical rads (AWR report) and tune them.
– Large no. of physical reads may be due to small DB_CACHE_SIZE – Use advisor to increase cache size
2. Average time for each read is high (> 15ms)
Soln:
– Avoid reading from disk
. Cache tables/indexes
. Use KEEP / RECYCLE pool
– Avoid reading from disk
. Cache tables/indexes
. Use KEEP / RECYCLE pool
– Stripe the datafiles for more bandwidth.
– Reduce checkpointing. Whenever there is a checkpoint, data is
written to disk. Since disk is busy servicing writes, reads get delayed.
Various read waits can be separately tuned as follows:
DB FILE SCATTERED READ
Waits for multiple blocks (up to DB_FILE_MULTIBLOCK_READ_COUNT) to be
read from disk while performing full table scans / Index fast full scans
(no order by) . This wait is encountered because:
-
As full table scans are pulled into memory, they are scattered
throughout the buffer cache , since it is highly unlikely that they fall
into contiguous buffers.
-
Since a large no. of blocks have to be read into the buffer cache,
server process has to search for a large no. of free/usable blocks in
buffer cache which leads to waits.
solutions :
- Try to cache frequently used small tables to avoid readingthem into memory over and overagain.
- Optimize multi-block I/O by setting the parameter DB_FILE_MULTIBLOCK_READ_COUNT
- Partition pruning: Partition tables/indexes so that only a partition is scanned.
- Consider the usage of multiple buffer pools
- Optimize the SQL statement that initiated most of the waits. The goal is to minimize the number of physical and logical reads.
. Should the statement access the data by a full table scan or index FFS?
. Would an index range or unique scan be more efficient?
. Does the query use the right driving table?
. Are the SQL predicates appropriate for hash or merge join?
. If full scans are appropriate, can parallel query improve the response time?
- Make sure all statistics are representative of the actual data. Check the LAST_ANALYZED date
The
objective is to reduce the demands for both the logical and physical
I/Os, and this is best achieved through SQL and application tuning.
DB FILE SEQUENTIAL READ
These waits generally indicate a single block read (e.g. Idex full scan : an index read with order by clause).
Causes and solutions :
1. Use of an unselective index
Soln:
- Check indexes on the table to ensure that the right index is being used
- Check the column order of the index with the WHERE clause of the Top SQL statements
2. Fragmented Indexes :
If the DBA_INDEXES.CLUSTERING_FACTOR of the index approaches the number
of blocks in the table, then most of the rows in the table are ordered.
This is desirable.
However,
if the clustering factor approaches the number of rows in the table, it
means the rows in the table are randomly ordered and thus it requires
more I/Os to complete the operation.
Soln:
You
can improve the index’s clustering factor by rebuilding the table so
that rows are ordered according to the index key and rebuilding the
index thereafter.
3. High I/O on a particular disk or mount point
Soln:
- Use in partitioning to reduce the amount of blocks being visited
- Make sure optimizer statistics are up to date
- Relocate ‘hot’ datafiles : Place the tables used in
the SQL statement on a faster part of the disk.
the SQL statement on a faster part of the disk.
- Consider the usage of multiple buffer pools and cache frequently used indexes/tables in the KEEP pool
- Inspect the execution plans of the SQL statements that access data through indexes
- Tune the I/O subsystem
to return data faster.
to return data faster.
4. Bad application design
Soln:
-
Optimize the SQL statement that initiated most of the waits. The goal
is to minimize the number of physical and logical reads.Inspect the
execution plans of the SQL statements that access data through indexes
1. Examine the SQL statement to see if
. it is doing a full-table scan when it should be using an index,
. it is using a wrong index or
. it can be rewritten to reduce the amount of data it retrieves
. it is appropriate for the SQL statements to access data through index lookups or would full table scan be more efficient?
. the statements use the right drivin table i.e. join order is proper?
5. Range scans on data spread in many different blocks
Soln:
- check that range scans should not be using reverse indexes.
- Load the data in sorted manner on the colums on which range scans will be there.
6. Consider increasing the buffer cache to see if the expanded size will accommodate the additional blocks, therefore reducing the I/O and the wait.
DB FILE PARALLEL READ
Waits for synchronous multiblock reads. The process has issued multiple
I/O requests in parallel to read from datafiles into memory (not during
parallel Query/DML) i.e. the process batches many single block I/O
requests together and issues them in parallel.
Some of the most common wait problems and potential solutions are outlined here:
Sequential Read Indicates many index reads—tune the code (especially joins)
Scattered Read Indicates many full table scans—tune the code; cache small tables
Free Buffer Increase the DB_CACHE_SIZE; shorten the checkpoint; tune the code
Buffer Busy Segment header—add freelists or freelist groups
Buffer Busy Data block—separate “hot” data; use reverse key indexes; use
smaller blocks; increase initrans (debatable); reduce block
popularity; make I/O faster
Buffer Busy Undo header—add rollback segments or areas
Buffer Busy Undo block—commit more; larger rollback segments or areas======================================================================
CLUSTERING FACTOR DEMYSTIFIED PART – II
CLUSTERING FACTOR DEMYSTIFIED PART – II
In my last post, CLUSTERING FACTOR DEMYSTIFIED PART – I‘,
I had explained what is clustering factor, how and why does it affect
the performance and had demonstrated it with the help of an example. I
had mentioned various methods to resolve the problem of a high
clustering factor.
Let’s explore the simplest one first i.e. CTAS with order by:
Overview:
- Create another ‘intermediate’ table from ‘unorganized’ table using CTAS order by
- Create ‘reorganized’ table from ‘ intermediate’ table using CTAS
- Create index on id column of ‘reorganized’ table
- Trace the same query and check that performance has improved
Implementation :
- Create another ‘intermediate’ table from ‘unorganized’ table using CTAS order by
SQL>create table intermediate as select * from unorganized order by id;
- Create ‘reorganized’ table from ‘ intermediate’ table using CTAS
SQL>create table reorganized as select * from intermediate;
drop table intermediate purge;
- Find out no. of blocks across which records of a key value are spread in the ‘reorganized’ table.
- Note that in ‘reorganized’ table, records are now clustered i.e. rows for a key value are placed together in blocks rather than scattered across various blocks
SQL> select reorg.id, reorg.cnt reorganized_block
from ( select id, count(distinct(dbms_rowid.ROWID_BLOCK_NUMBER(rowid))) cnt
from reorganized
group by id) reorg
order by id;
ID REORGANIZED_BLOCKS
———- ——————–
1 5
2 6
3 6
4 6
………
98 5
99 5
100 6
-- Create index on id column of ‘reorganized’ table and gather statistics for the table
SQL> create index reorganized_idx on reorganized(id); exec dbms_stats.gather_table_stats(USER, 'reorganized', estimate_percent => 100, method_opt=> 'for all indexed columns size 254');
– Check the index statistics
– Note that the index on table ‘reorganized‘
has a clustering factor (488) which is equal to the no. of rows in the
table i.e. to fetch all the records for various key values using
index, blocks need not be switched unless all the records in the
earlier block have been fetched
SQL>set line 500< col table_name for a15 > col index_name for a15 select blevel, leaf_blocks, table_name, index_name, clustering_factor from user_indexes where table_name like '%REORGANIZED%' order by 1;
BLEVEL LEAF_BLOCKS TABLE_NAME INDEX_NAME CLUSTERING_FACTOR
———- ———————– ——————- —————— ————————–
1 7 REORGANIZED REORGANIZED_IDX 488
- Trace the same query on ‘reorganized’ table and check that performance has improved
SQL> alter session set tracefile_identifier = 'cluster_factor'; alter session set sql_trace=true; select /*+ index(reorganized reorganized_idx) */ count(txt) from reorganized where id=id; alter session set sql_trace=false;
– Find out the name of trace file generated
SQL> col trace_file for a100 > select value trace_file from v$diag_info where upper(name) like '%TRACE FILE%';
TRACE_FILE
—————————————————————————————————-
/u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_29116_cluster_factor.trc
– Run tkprof utility on the trace file generated
$cd /u01/app/oracle/diag/rdbms/orcl/orcl/trace tkprof orcl_ora_29116_cluster_factor.trc cluster_factor.out vi cluster_factor.out
******************************************************************************
SQL ID: bmsnm1zh6audy
Plan Hash: 3677546845
select /*+ index(reorganized reorganized_idx) */ count(txt)
from
reorganized where id=id
Rows Row Source Operation
——- —————————————————
1 SORT AGGREGATE (cr=496 pr=328 pw=0 time=0 us)
3400 TABLE ACCESS BY INDEX ROWID REORGANIZED (cr=496pr=328 pw=0 time=42046 us cost=496 size=3073600 card=3400)
3400 INDEX FULL SCAN REORGANIZED_IDX (cr=8 pr=0 pw=0 time=9945 us cost=8 size=0 card=3400)(object id 75125)
******************************************************************************
Note that :
Total no. of I/Os performed against the index on ‘reorganized’ table = 8 (cr=8 in the INDEX FULL SCAN ORGANIZED_IDX row source)
Total I/O’s performed by the query = 496 (cr = 496 in the TABLE ACCESS BY INDEX ROWID ORGANIZED)
Hence , No. of I/O’s made against the table = 496 – 8 = 488 which is equal to the clustering factor of the index.
We can verify the improvement in performance by using autotrace on a query against the table:
SQL>set autotrace traceonly explain select /*+ index(reorganized reorganized_idx) */ count(txt) from reorganized where id=id; set autotrace off
————————————————————————————————
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
————————————————————————————————
| 0 | SELECT STATEMENT | | 1 | 904 | 496 (0)| 00:00:06 |
| 1 | SORT AGGREGATE | | 1 | 904 | | |
| 2 | TABLE ACCESS BY INDEX ROWID| REORGANIZED | 3400 | 3001K| 496 (0)| 00:00:06 |
|* 3 | INDEX FULL SCAN | REORGANIZED_IDX | 3400 | | 8 (0)| 00:00:01 |
————————————————————————————————
Note that there is a cost of 8 for using the index for the REORGANIZED table and index – about 8 I/O’s against the index i.e. the query will hit one root block (1)and the leaf blocks (7) .
Then the query will be doing 488 more I/Os against the table(= number of blocks in table), because the rows needed are all next to each other on a few database blocks, for a total cost of 496.
Hence. it can be seen that rows in a table can be physically
resequenced by using CTAS with order by. Here I would like to point out
that in this case, the table becomes unavailable while it is being
recreated. Hence, if availability of the table can’t be compromised,
this method is not preferable.
CLUSTERING FACTOR DEMYSTIFIED : PART – III
CLUSTERING FACTOR DEMYSTIFIED : PART – III
How to resolve the performance issues due to high clustering factor?
In my earlier post, Clustering Factor Demystified : Part – I,
I had discussed that to improve the Clustering Factor, the table must
be rebuilt (and reordered). The data retrieval can be considerably
speeded up by physically sequencing the rows in the same order as the
key column. If we can group together the rows for a key value, we can get all of the row with a single block read because the rows are together. To achieve this goal, various methods may be used. In the post Clustering Factor Demystified : Part -II, I had demonstratedManual Row Re-sequenciung (CTAS with order by) which pre-orders data to avoid expensive disk sorts after retrieval. In this post, I will demonstrate the use of Single table hash clusters and Single table index clusters which clusters related rows together onto the same data block .
Overview:
- Create a table organized which contains two columns - id(number) and txt (char)- Populate the table insert 34 records for each value of id where id ranges from 1 to 100- In this case as records are added sequentially, records for a key value are stored together
- Create another table unorganized which is a replica of the ‘organized’ table but records are inserted in a random manner so that records for a key value may be scattered across different blocks .
- Create a single table index cluster table from ‘unorganized’ table using CTAS.
- Create a single table hash cluster table from ‘unorganized’ table using CTAS
- Trace the query using exact match on three tables and verify that hash cluster table gives the best performance .
- Trace the query using range scan on three tables and verify that index cluster table gives the best performance .
- Verify that index and hash cluster tables have better clustering factor .
Implementation:
- Create a table organized which contains two columns – id(number) and txt (char)
– Populate the table insert 34 records for each value of id where id ranges from 1 to 100
– In this case as records are added sequentially, records for a key value are stored together
– Populate the table insert 34 records for each value of id where id ranges from 1 to 100
– In this case as records are added sequentially, records for a key value are stored together
SQL> drop table organized purge;
create table organized (id number(3), txt char(900));
begin
for i in 1..100 loop
insert into organized select i, lpad(‘x’, 900, ‘x’)
from dba_objects where rownum < 35;
end loop;
end;
/
create table organized (id number(3), txt char(900));
begin
for i in 1..100 loop
insert into organized select i, lpad(‘x’, 900, ‘x’)
from dba_objects where rownum < 35;
end loop;
end;
/
- create another
table unorganized which is a replica of the ‘organized’ table but
records are inserted in a random manner so that records for a key value
may be scattered across different blocks (order by dbms_random.random).
SQL> drop table unorganized purge;
create table unorganized as select * from organized order by dbms_random.random;
create table unorganized as select * from organized order by dbms_random.random;
create index unorganized_idx on unorganized(id);
exec dbms_stats.gather_table_stats(USER, ‘unorganized’, estimate_percent => 100, method_opt=> ‘for all indexed columns size 254′);
– Create a single table index cluster table from ‘unorganized’ table using CTAS.
— Create a cluster with size = blocksize = 8k and index it
SQL> drop cluster index_cluster including tables;
create cluster index_cluster
( id number(3) )
size 8192;
create cluster index_cluster
( id number(3) )
size 8192;
create index index_cluster_idx
on cluster index_cluster;
drop table index_cluster_tab purge;
create table index_cluster_tab
cluster index_cluster( id )
as select * from unorganized ;
cluster index_cluster( id )
as select * from unorganized ;
– Create a single table hash cluster table from ‘unorganized’ table using CTAS
SQL>drop tablespace mssm including contents and datafiles;
Create tablespace mssm datafile ‘/u01/app/oracle/oradata/orcl/mssm01.dbf’ size 100m segment space management manual;
drop cluster hash_cluster including tables;
create cluster Hash_cluster
( id number(3) )
size 8192 single table hash is id hashkeys 100 tablespace mssm;
create cluster Hash_cluster
( id number(3) )
size 8192 single table hash is id hashkeys 100 tablespace mssm;
drop table hash_cluster_tab purge;
create table hash_cluster_tab cluster hash_cluster(id)
as select * from unorganized;
begin
dbms_stats.gather_table_stats
( user, ‘UNORGANIZED’, cascade=>true ); dbms_stats.gather_table_stats
( user, ‘INDEX_CLUSTER_TAB’, cascade=>true ); dbms_stats.gather_table_stats
( user, ‘HASH_CLUSTER_TAB’, cascade=>true );
End;
/
dbms_stats.gather_table_stats
( user, ‘UNORGANIZED’, cascade=>true ); dbms_stats.gather_table_stats
( user, ‘INDEX_CLUSTER_TAB’, cascade=>true ); dbms_stats.gather_table_stats
( user, ‘HASH_CLUSTER_TAB’, cascade=>true );
End;
/
- Find out no. of blocks across which records of a key value are spread in the two tables.-
Note that in ‘unorganized’ table, records for an id are scattered
across more than 30 blocks whereas in index_cluster_tab and
hash_cluster_tab tables, records for each id are clustered i.e. records
for each key value are spread across 5 blocks only.
SQL> select unorg.id id, unorg.cnt unorganized_blocks,
idx_tab.cnt index_cluster_blocks, hash_tab.cnt hash_cluster_blocks
from
( select id, count(distinct(dbms_rowid.ROWID_BLOCK_NUMBER(rowid))) cnt
from unorganized
group by id) unorg,
( select id, count(distinct(dbms_rowid.ROWID_BLOCK_NUMBER(rowid))) cnt
from index_cluster_tab
group by id) idx_tab,
( select id, count(distinct(dbms_rowid.ROWID_BLOCK_NUMBER(rowid))) cnt
from hash_cluster_tab
group by id) hash_tab
where idx_tab.id = unorg.id
and hash_tab.id = unorg.id
order by id;
idx_tab.cnt index_cluster_blocks, hash_tab.cnt hash_cluster_blocks
from
( select id, count(distinct(dbms_rowid.ROWID_BLOCK_NUMBER(rowid))) cnt
from unorganized
group by id) unorg,
( select id, count(distinct(dbms_rowid.ROWID_BLOCK_NUMBER(rowid))) cnt
from index_cluster_tab
group by id) idx_tab,
( select id, count(distinct(dbms_rowid.ROWID_BLOCK_NUMBER(rowid))) cnt
from hash_cluster_tab
group by id) hash_tab
where idx_tab.id = unorg.id
and hash_tab.id = unorg.id
order by id;
ID UNORGANIZED_BLOCKS INDEX_CLUSTER_BLOCKS HASH_CLUSTER_BLOCKS
———- —————— ——————– ——————-
1 33 5 5
2 34 5 5
3 33 5 5
4 33 5 5
5 33 5 5
6 32 5 5
7 34 5 5
8 34 5 5
9 33 5 5
10 32 5 5
…
90 34 5 5
91 34 5 5
92 30 5 5
93 34 5 5
94 34 5 5
95 34 5 5
96 34 5 5
97 33 5 5
98 33 5 5
99 34 5 5
100 34 5 5
- Trace the query using exact match on three tables and verify that hash cluster table gives the best performance .
– Let’s compare the statistics when rows for all the id’s are retrieved in succession from the three tables
conn / as sysdba
alter session set tracefile_identifier = ‘cluster_factor';
alter session set sql_trace=true;
declare
type tab_row is table of unorganized%rowtype;
tab_rows tab_row;
type id_val is table of unorganized.id%type;
id_vals id_val;
type tab_row is table of unorganized%rowtype;
tab_rows tab_row;
type id_val is table of unorganized.id%type;
id_vals id_val;
begin
select distinct id bulk collect into id_vals
from unorganized; for k in id_vals.first .. id_vals.last
loop
select * bulk collect into tab_rows
from unorganized
where id = k;
end loop;
end;
/
select distinct id bulk collect into id_vals
from unorganized; for k in id_vals.first .. id_vals.last
loop
select * bulk collect into tab_rows
from unorganized
where id = k;
end loop;
end;
/
declare
type tab_row is table of index_cluster_tab%rowtype;
tab_rows tab_row;
type id_val is table of index_cluster_tab.id%type;
id_vals id_val; begin
select distinct id bulk collect into id_vals
from index_cluster_tab; for k in id_vals.first .. id_vals.last
loop
select * bulk collect into tab_rows
from index_cluster_tab
where id = k;
end loop;
end;
/declare
type tab_row is table of hash_cluster_tab%rowtype;
tab_rows tab_row;
type id_val is table of hash_cluster_tab.id%type;
id_vals id_val; begin
select distinct id bulk collect into id_vals
from hash_cluster_tab; for k in id_vals.first .. id_vals.last
loop
select * bulk collect into tab_rows
from hash_cluster_tab
where id = k;
end loop;
end;
/
type tab_row is table of index_cluster_tab%rowtype;
tab_rows tab_row;
type id_val is table of index_cluster_tab.id%type;
id_vals id_val; begin
select distinct id bulk collect into id_vals
from index_cluster_tab; for k in id_vals.first .. id_vals.last
loop
select * bulk collect into tab_rows
from index_cluster_tab
where id = k;
end loop;
end;
/declare
type tab_row is table of hash_cluster_tab%rowtype;
tab_rows tab_row;
type id_val is table of hash_cluster_tab.id%type;
id_vals id_val; begin
select distinct id bulk collect into id_vals
from hash_cluster_tab; for k in id_vals.first .. id_vals.last
loop
select * bulk collect into tab_rows
from hash_cluster_tab
where id = k;
end loop;
end;
/
– Find out the name of trace file generatedSQL> col trace_file for a100
select value trace_file from v$diag_info
where upper(name) like ‘%TRACE FILE%';
TRACE_FILE
—————————————————————————————————
/u01/app/oracle/diag/rdbms/orcl1/orcl1/trace/orcl1_ora_24963_cluster_factor.trc– Run tkprof utility on the trace file generated $cd /u01/app/oracle/diag/rdbms/orcl/orcl/trace
rm cluster_factor.out tkprof /u01/app/oracle/diag/rdbms/orcl1/orcl1/trace/orcl1_ora_8403_cluster_factor.trc cluster_factor.out
vi cluster_factor.out
********************************************************************************
Here are the contents of the trace file:
Here are the contents of the trace file:
In case of unorganized table, it
can be seen that no. of blocks visited (3517) is approaches the number
of rows (3400) in the table as rows for an id are scattered across a
large no. of blocks.
SQL ID: 0npa78p7jkfa5
Plan Hash: 1120857569
SELECT *
FROM
UNORGANIZED WHERE ID = :B1
FROM
UNORGANIZED WHERE ID = :B1
call count cpu elapsed disk query current rows
——- —— ——– ———- ———- ———- ———- ———-
Parse 1 0.00 0.00 0 0 0 0
Execute 100 0.00 0.00 0 0 0 0
Fetch 100 0.01 0.02 0 3517 0 3400
——- —— ——– ———- ———- ———- ———- ———-
total 201 0.01 0.02 0 3517 0 3400
——- —— ——– ———- ———- ———- ———- ———-
Parse 1 0.00 0.00 0 0 0 0
Execute 100 0.00 0.00 0 0 0 0
Fetch 100 0.01 0.02 0 3517 0 3400
——- —— ——– ———- ———- ———- ———- ———-
total 201 0.01 0.02 0 3517 0 3400
*******************************************************************************
In case of single table index cluster,
Total I/O’s = I/O’s against the table + I/O’s against the table
In case of single table index cluster,
Total I/O’s = I/O’s against the table + I/O’s against the table
i/O’s against the table = no. of table blocks across which various records for different id’s are stored
Since we saw earlier that records for each key value are scattered across 5 blocks,
I/O’s against the table = no. of distinct key values (id’s) * no. of blocks occupied by records for an id
= 100 * 5
= 500
= 100 * 5
= 500
Rest 100 I/O’s are made against against the index ( one I/O for each key value)
Hence total I/O’s = 100 + 500 = 600
********************************************************************************
********************************************************************************
SQL ID: 6qy378ww4729s
Plan Hash: 3651720007
SELECT *
FROM
INDEX_CLUSTER_TAB WHERE ID = :B1
Plan Hash: 3651720007
SELECT *
FROM
INDEX_CLUSTER_TAB WHERE ID = :B1
call count cpu elapsed disk query current rows
——- —— ——– ———- ———- ———- ———- ———-
Parse 1 0.00 0.00 0 0 0 0
Execute 100 0.00 0.00 0 0 0 0
Fetch 100 0.00 0.00 0 600 0 3400
——- —— ——– ———- ———- ———- ———- ———-
total 201 0.00 0.00 0 600 0 3400
——- —— ——– ———- ———- ———- ———- ———-
Parse 1 0.00 0.00 0 0 0 0
Execute 100 0.00 0.00 0 0 0 0
Fetch 100 0.00 0.00 0 600 0 3400
——- —— ——– ———- ———- ———- ———- ———-
total 201 0.00 0.00 0 600 0 3400
*******************************************************************************
In case of single table hash cluster, as index access is not needed,
Total I/O’s = I/O’s against the table
= no. of distinct key values (id’s) * no. of blocks occupied by records for an id
= 100 * 5
= 500
********************************************************************************
In case of single table hash cluster, as index access is not needed,
Total I/O’s = I/O’s against the table
= no. of distinct key values (id’s) * no. of blocks occupied by records for an id
= 100 * 5
= 500
********************************************************************************
SQL ID: ctnu91v20p2x2
Plan Hash: 3860562250
SELECT *
FROM
HASH_CLUSTER_TAB WHERE ID = :B1
FROM
HASH_CLUSTER_TAB WHERE ID = :B1
call count cpu elapsed disk query current rows
——- —— ——– ———- ———- ———- ———- ———-
Parse 1 0.00 0.00 0 0 0 0
Execute 100 0.00 0.00 0 0 0 0
Fetch 100 0.00 0.00 0 500 0 3400
——- —— ——– ———- ———- ———- ———- ———-
total 201 0.00 0.00 0 500 0 3400
——- —— ——– ———- ———- ———- ———- ———-
Parse 1 0.00 0.00 0 0 0 0
Execute 100 0.00 0.00 0 0 0 0
Fetch 100 0.00 0.00 0 500 0 3400
——- —— ——– ———- ———- ———- ———- ———-
total 201 0.00 0.00 0 500 0 3400
*******************************************************************************
Summarizing the above results :
unorganized index_cluster_tab hash_cluster_tab
total CPU 0.01 0.00 0.00
total CPU 0.01 0.00 0.00
elapsed 0.01 0.02 0.00
time
time
I/O’s 3517 600 500
Hence, it can be concluded that for
exact match queries hash clusters give the best performance since least
no. of I/O’s are made.
- Trace the query using range scan on three tables and verify that index cluster table gives the best performance .
– Let’s compare the statistics when rows for entire range of id’s are retrieved from the three tables
conn / as sysdba
alter session set
tracefile_identifier = ‘cluster_factor';
tracefile_identifier = ‘cluster_factor';
alter session set
sql_trace=true;
sql_trace=true;
declare
type tab_row is table of
unorganized%rowtype;
unorganized%rowtype;
tab_rows tab_row;
type id_val is table of
unorganized.id%type;
unorganized.id%type;
id_vals id_val;
begin
select distinct id bulk collect into id_vals
from unorganized;
for j in id_vals.first..id_vals.first loop
for k in id_vals.last .. id_vals.last loop
select * bulk collect into tab_rows
from unorganized
where id >= j and id <= k;
end loop;
end loop;
end;
/
declare
type tab_row is table of index_cluster_tab%rowtype;
tab_rows tab_row;
type id_val is table of index_cluster_tab.id%type;
id_vals id_val;
begin
select distinct id bulk collect into id_vals
from index_cluster_tab;
for j in id_vals.first..id_vals.first loop
for k in id_vals.last .. id_vals.last loop
select * bulk collect into tab_rows
from index_cluster_tab
where id >= j and id <= k;
end loop;
end loop;
end;
/
declare
type tab_row is table of hash_cluster_tab%rowtype;
tab_rows tab_row;
type id_val is table of hash_cluster_tab.id%type;
id_vals id_val;
begin
select distinct id bulk collect into id_vals
from hash_cluster_tab;
for j in id_vals.first..id_vals.first loop
for k in id_vals.last .. id_vals.last loop
select * bulk collect into tab_rows
from hash_cluster_tab
where id >= j and id <= k;
end loop;
end loop;
end;
/
– Find out the name of trace file generated
SQL> col
trace_file for a100
trace_file for a100
select value trace_file from v$diag_info
where upper(name) like ‘%TRACE
FILE%';
FILE%';
TRACE_FILE
—————————————————————————————————-
/u01/app/oracle/diag/rdbms/orcl1/orcl1/trace/orcl1_ora_24963_cluster_factor.trc
– Run tkprof utility on the trace file generated
$cd /u01/app/oracle/diag/rdbms/orcl/orcl/trace
rm cluster_factor.out
tkprof /u01/app/oracle/diag/rdbms/orcl1/orcl1/trace /orcl1_ora_8403_cluster_factor.trc cluster_factor.out
vi cluster_factor.out
Here are the contents of the trace file:
In case of unorganized table, it can be seen that Full table scan is done and
total I/O’s = Physical I/O’s + logical I/O’s
= 486 + 489 = 975
CPU usage = 0.01
elapsed time = 0.01
cost = 127
********************************************************************************
SQL ID:
dpg9s5v7jannv
dpg9s5v7jannv
Plan Hash:
3859503019
3859503019
SELECT *
FROM
UNORGANIZED WHERE ID >= :B2 AND ID <=
:B1
:B1
call count
cpu elapsed disk
query current rows
cpu elapsed disk
query current rows
——-
—— ——– ———- ———-
———- ———- ———-
—— ——– ———- ———-
———- ———- ———-
Parse 1
0.00 0.00 0 0 0 0
0.00 0.00 0 0 0 0
Execute 1
0.00 0.00 0 0 0 0
0.00 0.00 0 0 0 0
Fetch 1
0.01 0.01 486 489 0 3400
0.01 0.01 486 489 0 3400
——-
—— ——– ———- ———-
———- ———- ———-
—— ——– ———- ———-
———- ———- ———-
total 3
0.01 0.01 486 489 0 3400
0.01 0.01 486 489 0 3400
Rows Row Source Operation
——-
—————————————————
—————————————————
3400
FILTER (cr=489 pr=486 pw=0
time=3524 us)
FILTER (cr=489 pr=486 pw=0
time=3524 us)
3400
TABLE ACCESS FULL UNORGANIZED (cr=489 pr=486 pw=0 time=1888 us cost=127size=3073600 card=3400)
TABLE ACCESS FULL UNORGANIZED (cr=489 pr=486 pw=0 time=1888 us cost=127size=3073600 card=3400)
********************************************************************************
In case of index cluster table, it can be seen that index range scan is performed on cluster index followed by table access cluster.
total I/O’s = Physical I/O’s + logical I/O’s
= 385 + (501 + 1)
= 887
CPU usage = 0.01
elapsed time = 0.01
cost = 101
*******************************************************************************
SQL ID:
22k91ut1b18nj
22k91ut1b18nj
Plan Hash:
533030663
533030663
SELECT *
FROM
INDEX_CLUSTER_TAB WHERE ID >= :B2 AND ID
<= :B1
<= :B1
call count
cpu elapsed disk
query current rows
cpu elapsed disk
query current rows
——-
—— ——– ———- ———-
———- ———- ———-
—— ——– ———- ———-
———- ———- ———-
Parse 1
0.00 0.00 0 0 0 0
0.00 0.00 0 0 0 0
Execute 1
0.00 0.00 0 0 0 0
0.00 0.00 0 0 0 0
Fetch 1
0.01 0.01 385 501 0 3400
0.01 0.01 385 501 0 3400
——-
—— ——– ———- ———-
———- ———- ———-
—— ——– ———- ———-
———- ———- ———-
total 3 0.01
0.01 385 501 0 3400
0.01 385 501 0 3400
Misses in library
cache during parse: 1
cache during parse: 1
Optimizer mode:
ALL_ROWS
ALL_ROWS
Parsing user id:
SYS (recursive depth: 1)
SYS (recursive depth: 1)
Rows Row Source Operation
——- —————————————————
3400
FILTER (cr=501 pr=385 pw=0
time=9441 us)
FILTER (cr=501 pr=385 pw=0
time=9441 us)
3400
TABLE ACCESS CLUSTER INDEX_CLUSTER_TAB (cr=501 pr=385 pw=0 time=7679 us
cost=101 size=3073600 card=3400)
TABLE ACCESS CLUSTER INDEX_CLUSTER_TAB (cr=501 pr=385 pw=0 time=7679 us
cost=101 size=3073600 card=3400)
100
INDEX RANGE SCAN INDEX_CLUSTER_IDX (cr=1 pr=0 pw=0 time=99 us cost=1
size=0 card=1)(object id 80458)
INDEX RANGE SCAN INDEX_CLUSTER_IDX (cr=1 pr=0 pw=0 time=99 us cost=1
size=0 card=1)(object id 80458)
********************************************************************************
In case of hash cluster table, it can be seen that hash access is made to the table.
total I/O’s = Physical I/O’s + logical I/O’s
= 503 + 506
= 1009
CPU usage = 0.04
elapsed time = 0.04
cost = 132
*******************************************************************************
SQL ID:
c2www0m7npkqp
c2www0m7npkqp
Plan Hash:
4115468836
4115468836
SELECT *
FROM
HASH_CLUSTER_TAB WHERE ID >= :B2 AND ID
<= :B1
<= :B1
call count
cpu elapsed disk
query current rows
cpu elapsed disk
query current rows
——-
—— ——– ———- ———-
———- ———- ———-
—— ——– ———- ———-
———- ———- ———-
Parse 1
0.00 0.00 0 0 0 0
0.00 0.00 0 0 0 0
Execute 1
0.00 0.00 0 0 0 0
0.00 0.00 0 0 0 0
Fetch 1
0.04 0.04 503 506 0 3400
0.04 0.04 503 506 0 3400
——-
—— ——– ———- ———-
———- ———- ———-
—— ——– ———- ———-
———- ———- ———-
total 3
0.04 0.04 503 506 0 3400
0.04 0.04 503 506 0 3400
Misses in library
cache during parse: 1
cache during parse: 1
Optimizer mode:
ALL_ROWS
ALL_ROWS
Parsing user id:
SYS (recursive depth: 1)
SYS (recursive depth: 1)
Rows Row Source Operation
——-
—————————————————
—————————————————
3400
FILTER (cr=506 pr=503 pw=0
time=39906 us)
FILTER (cr=506 pr=503 pw=0
time=39906 us)
3400
TABLE ACCESS FULL HASH_CLUSTER_TAB (cr=506 pr=503 pw=0 time=37389 us
cost=132 size=3073600 card=3400)
TABLE ACCESS FULL HASH_CLUSTER_TAB (cr=506 pr=503 pw=0 time=37389 us
cost=132 size=3073600 card=3400)
********************************************************************************
Summarizing above results :
unorganized index_cluster_tab hash_cluster_tab
total I/O’s 975 887 1009
CPU usage 0.01 0.01 0.04
elapsed time 0.01 0.01 0.04
cost 127 101 132
Hence, to search a range of values, single table index cluster is the best choice.
CPU usage, I/O’s and cost is the maximum in case of single table hash cluster table.
- Verify that index and hash cluster tables have better clustering factor .
Let’s compare clustering factor of indexes on the three tables.
Tables unorganized and index_cluster_tab already have index.
– Let’s create index on hash_cluster_tab and gather statistics .
SQL>create index hash_cluster_idx on hash_cluster_tab(id);
exec dbms_stats.gather_index_stats(USER, ‘HASH_CLUSTER_IDX’);
exec dbms_stats.gather_index_stats(USER, ‘INDEX_CLUSTER_IDX’);
– Find out clustering factor of the three tables.
SQL> select index_name, clustering_factor
from user_indexes
where index_name in (‘UNORGANIZED_IDX’, ‘INDEX_CLUSTER_IDX’, ‘HASH_CLUSTER_IDX’);
INDEX_NAME CLUSTERING_FACTOR
—————————— —————–
HASH_CLUSTER_IDX 500
INDEX_CLUSTER_IDX 100
UNORGANIZED_IDX 3311
– Note that
– clustering factor of index on unorganized table approaches no. of rows in the table (3400).
– clustering factor of index on hash_cluster_tab table = 500 . As
entries for each id are spread across 5 blocks, 500 blocks need to be
accessed to get all the rows and index is aware of this information.
– clustering factor of index on index_cluster_tab table = 100 as there
are 100 entries (one for each id) in the index. Here also 500 table
blocks need to be accessed to get all the rows but index contains
information about only the first(or may be the last) data block for an
id. Rest 4 blocks containing records for that id are chained to it and
index does not have that information and clustering factor of an index
is computed on the basis of the information available in the index.
That’s why clustering factor in this case = no. of index entries.
SUMMARY:
- Clustered tables cannot be truncated.
- Choosing the Key :Choosing the correct cluster key is dependent on the most common types of queries issued against the clustered tables. The cluster key should be on the column against which queries are most commonly issued.
HASH CLUSTERS
A hash
cluster stores related rows together in the same data blocks. Rows in a
hash cluster are stored together based on their hash value.
- – Hash clusters are a great way to reduce IO on some tables, but they have their downside.
*If too little space is reserved for each
key (small SIZE value), or if the cluster is created with too few hash keys (small HASHKEYS), then each key will split across multiple blocks negating the benefits of the cluster.When creating a hash cluster, it is important to choose the cluster key correctly and set the HASH IS, SIZE, and HASHKEYS parameters so that performance and space use are optimal.
* If too much space is reserved for each key (large SIZE value), or if the cluster is created with too many hash keys (large
HASHKEYS), then the cluster will contain thousands of empty blocks that slow down full table scans . A SIZE value much larger results in wasted space.
key (small SIZE value), or if the cluster is created with too few hash keys (small HASHKEYS), then each key will split across multiple blocks negating the benefits of the cluster.When creating a hash cluster, it is important to choose the cluster key correctly and set the HASH IS, SIZE, and HASHKEYS parameters so that performance and space use are optimal.
* If too much space is reserved for each key (large SIZE value), or if the cluster is created with too many hash keys (large
HASHKEYS), then the cluster will contain thousands of empty blocks that slow down full table scans . A SIZE value much larger results in wasted space.
- Hash clusters reduce contention and I/O since index is not accessed .When you use an index range scan + table access by index rowid, the root index block becomes a “hot block” causing contention for the cache buffers chains (cbc) latch and hence an increase in CPU usage.
- Hashing works best for exact match searches i.e. SELECT … WHERE cluster_key = …;
A properly sized hash cluster for a lookup table gives pretty much a SINGLE IO for a keyed lookup.
- Hash clusters should only really be used for tables which are static in size so that you can determine the number of rows and amount of space required for the tables in the cluster. If tables in a hash cluster require more space than the initial allocation for the cluster, performance degradation can be substantial because overflow blocks are required.
- Hash
clusters should only really be used for tables which have mostly
read-only data. The hash cluster will take marginally longer
to insert into since the data now has a “place” to go and maintaining this structure will take longer then maintaining a HEAP table .Updates do not provide much overhead unless the hashkey is being updated. - Hash clusters should not be used in applications where most queries on the table retrieve rows over a range of cluster key values where a hash function cannot be used to determine the location of specific hash keys and instead, the equivalent of a full table scan must be done to fetch the rows for the query:
- Hash clusters should not be used in applications where hash key is updated. The hashing values can not be recalculated and thus serious overflow can result.
- Hash clusters should not be used for tables which are not static and continually growing. If a table grows without limit, the space required over the life of the table (its cluster) cannot be predetermined.
- Hash clusters should not be used for when you cannot afford to pre-allocate the space that the hash cluster will eventually
need. - Hash clusters allocate all the storage for all the hash buckets when the cluster is created, so they may waste space.
- Full scans on single table hash clusters will cost as much as they would in a heap table.
INDEX CLUSTERS
In an
indexed cluster, Oracle stores together rows having the same cluster key
value. Each distinct cluster key value is stored only once in each data
block, regardless of the number of tables and rows in which it occurs.
This saves disk space and improves performance for many operations.
- Index clusters should be used for the apllications where most queries on the table retrieve rows over a range of cluster key values. For example, in full table scans or queries such as the following:
SELECT . . . WHERE cluster_key < . . . ;
- With an index, key values are ordered in the index, so cluster key values that satisfy the WHERE clause of a query can be found with relatively few I/Os.
- Index clusters should be used for the tables which are not static, but instead are continually growing and the space required over the life of the table (its cluster) cannot be predetermined.
- Index clusters should be used for applications which frequently perform full-table scans on the table and the table is sparsely populated. A full-table scan in this situation takes longer under hashing.
- Cluster index has one entry per cluster key and not for each row. Therefore, the index is smaller and less costly to access for finding multiple rows.
=====================================================